
 payment page
payment pageAs we saw with binary search, certain data structures such as a binary search tree can help improve the efficiency of searches. From linear search to binary search, we improved our search efficiency from O(n) to O(logn). We now present a new data structure, called a hash table, that will increase our efficiency to O(1), or constant time.
A hash table is made up of two parts: an array (the actual table where the data to be searched is stored) and a mapping function, known as a hash function. The hash function is a mapping from the input space to the integer space that defines the indices of the array. In other words, the hash function provides a way for assigning numbers to the input data such that the data can then be stored at the array index corresponding to the assigned number.
Let's take a simple example. First, we start with a hash table array of strings (we'll use strings as the data being stored and searched in this example). Let's say the hash table size is 12:

Next we need a hash function. There are many possible ways to construct a hash function. We'll discuss these possibilities more in the next section. For now, let's assume a simple hash function that takes a string as input. The returned hash value will be the sum of the ASCII characters that make up the string mod the size of the table:
Now that we have a framework in place, let's try using it. First, let's store a string into the table: "Steve". We run "Steve" through the hash function, and find that hash("Steve",12) yields 3:

Let's try another string: "Spark". We run the string through the hash function and find that hash("Spark",12) yields 6. Fine. We insert it into the hash table:

Let's try another: "Notes". We run "Notes" through the hash function and find that hash("Notes",12) is 3. Ok. We insert it into the hash table:

What happened? A hash function doesn't guarantee that every input will map to a different output (in fact, as we'll see in the next section, it shouldn't do this). There is always the chance that two inputs will hash to the same output. This indicates that both elements should be inserted at the same place in the array, and this is impossible. This phenomenon is known as a collision.
There are many algorithms for dealing with collisions, such as linear probing an d separate chaining. While each of the methods has its advantages, we will only discuss separate chaining here.
Separate chaining requires a slight modification to the data structure. Instead of storing the data elements right into the array, they are stored in linked lists. Each slot in the array then points to one of these linked lists. When an element hashes to a value, it is added to the linked list at that index in the array. Because a linked list has no limit on length, collisions are no longer a problem. If more than one element hashes to the same value, then both are stored in that linked list.
Let's look at the above example again, this time with our modified data structure:
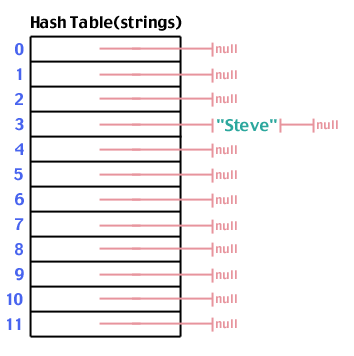
Again, let's try adding "Steve" which hashes to 3:
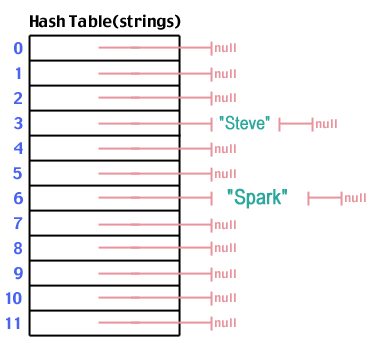
And "Spark" which hashes to 6:
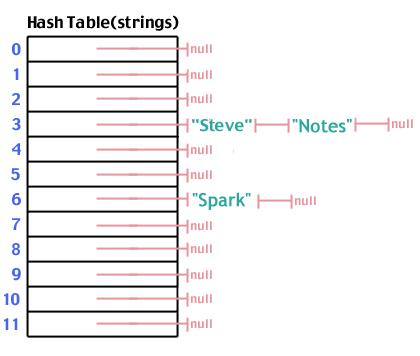
Now we add "Notes" which hashes to 3, just like "Steve":
Once we have our hash table populated, a search follows the same steps as doing an insertion. We hash the data we're searching for, go to that place in the array, look down the list originating from that location, and see if what we're looking for is in the list. The number of steps is O(1).
Separate chaining allows us to solve the problem of collision in a simple yet powerful manner. Of course, there are some drawbacks. Imagine the worst case scenario where through some fluke of bad luck and bad programming, every data element hashed to the same value. In that case, to do a lookup, we'd really be doing a straight linear search on a linked list, which means that our search operation is back to being O(n). The worst case search time for a hash table is O(n). However, the probability of that happening is so small that, while the worst case search time is O(n), both the best and average cases are O(1).



