
 payment page
payment pageStrings are prevalent in computer programs. As such, languages often contain built-in functions for handling strings; C is no different. The standard library contains functions for dealing with and manipulating strings (to include this library, you would include the string.h library).
Why bring this up in a recursion tutorial? The manipulation of strings is a perfect testing ground for recursive and iterative techniques, due to their repetitive nature (a sequence of successive characters in memory, terminated by a '\0'). Other data structures are inherently recursive, meaning that the data structure refers to itself, allowing for easy manipulation through recursive algorithms; we'll examine these later.
If you were to actually examine how the C string library is implemented, you would almost definitely find it done with iteration (as the coding and understanding complexity of the functions are similar in both the recursive and iterative versions, a programmer would opt to use iteration as it would require fewer system resources, such as less memory on the call stack). That being said, we will examine how different functions from the string library can be written using both techniques, so you can see how they relate. The best way to get a handle on recursion is to practice it a lot.
We'll start with the most basic of the string functions, the strlen() function, which determines the length of a string passed to it. Intuitively, this function counts how many characters there are before the terminating '\0' character. This approach lends itself to an iterative implementation:
The code starts at the beginning of the string, with a count of 0, and for each character until the '\0' it increments the count by 1, returning the final count.
Let's look at this from a recursive standpoint. We break the string into two parts: the small problem we know how to solve, and the smaller version of the big problem that we will solve recursively. In the case of strlen(), the small problem we know how to solve is a single character; for a single character we add one to the count of the rest of the string. The other problem, the smaller version of the original, is the rest of the string following the character at the beginning of the string.
Our algorithm will be as follows: if the string passed to us is empty (meaning it only contains the '\0' character), then the string is 0 characters long, so return 0; otherwise, we count the current character by adding 1 to the result of recursively strlen()'ing the rest of the string.
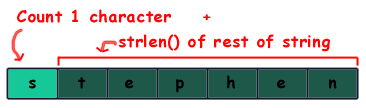
Not so bad, right? Try going through a few different strings by hand, using both the iterative and recursive approaches, so that you fully understand what is going on. In addition, when doing the recursive version, draw out a representation of the call stack to see the argument to and the return value from each call.
Let's try another function, strcmp(). strcmp() takes two strings as arguments, and returns a number representing whether or not they are equal. If the return value is 0, that means the strings are the same. If the return value is less than 0, that means that the first string is alphabetically lower than the second ('a' < 'z'). And if the return value is greater than 0, that means the first string is alphabetically greater than the second.
Again, let's first do it iteratively. We walk along each string at the same pace, comparing the first character of the first string to the first character of the second string, the second character of the first string to the second character of the second string, etc. This continues until we reach a \0 in one of the strings or until in one of our comparisons, the characters are not the same. At this point, we compare the current characters. If we stopped because we reached a \0, then if the other string also has a \0, the two strings are equal. Otherwise, we need to devise a way to easily compute which string is the "greater" one.
A neat trick: subtract the current character of the first string from the current character of the second string. This avoids using multiple if-else statements.
Note that we don't have to do (*s==*t && *t!='\0' && *s!='\0') as the conditional; we just leave out the t!='\0'. Why can we do this? Let's think about it... what are the different possibilities?
- both *s and *t are '\0' -> the *s!='\0' will cover this case
- *s is '\0' and *t is not '\0' -> the *s!='\0' will cover this case
- *t is '\0' and *s is not '\0' -> the *s!=*t case will cover this
- both *s and *t are not '\0' -> the *s!=*t case will cover this
The recursive version of the function is very similar to the iterative version. We look at the characters at the front of the strings passed to us; if one is '\0' or if the two characters are different, we return their difference. Otherwise, the two characters are the same, and we've reduced this to the problem of doing a string comparison on the rest of the string, so we recursively call our strcmp() function on the remainder of each string.
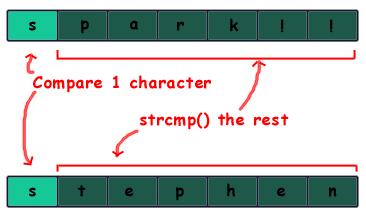
The string library also contains a version of the strcmp() function that allows a progammer to compare only a certain number of characters from each string, the strncmp() function. To implement this function, we add another argument, the number of characters to compare. /PARAGRPH Iteratively, this function is almost identical to the normal strcmp() except that we keep track of how many characters we have counted. We add the count variable that starts out at 0. Every time we look at another character we increment count, and we add another condition to the loop, that our count must be less than than the argument specifying the length to examine.
Similarly, the recursive implementation requires only a minor change. Each time we make the recursive call, we subtract 1 from the argument specifying the length to examine. Then in our condition we check to see if n==0.
All the other functions in the string library can be implemented with a similar style. We present another few here with iterative and recursive implementations side by side so that you can easily examine and compare them.
String copy: strcpy() Given two strings, one destination and one source, copy the source string to the destination string. One important caveat: the destination string must have enough memory allocated to hold the copied source string.
Iterative
Recursive:
String copy with length restriction: strncpy() This function is to strcpy() as strncmp() is to strcmp(): it will copy from the source string to the destination string no more than the specified number of characters.
Iterative:
Recursive:
String search: strstr() This function searches for one string embedded within another string and returns a pointer in the larger string to the location of the smaller string, returning NULL if the search string was not found.
Iterative:
Recursive:
Character search within a string: strchr() This function searches for the first occurrence of a character within a string.



