Did you know you can highlight text to take a note?
x

Suggestions
Use up and down arrows to review and enter to select.Please wait while we process your payment
If you don't see it, please check your spam folder. Sometimes it can end up there.
If you don't see it, please check your spam folder. Sometimes it can end up there.
Please wait while we process your payment
By signing up you agree to our terms and privacy policy.
Don’t have an account? Subscribe now
Create Your Account
Sign up for your FREE 7-day trial
Already have an account? Log in
Your Email
Choose Your Plan
Individual
Group Discount
Save over 50% with a SparkNotes PLUS Annual Plan!
 payment page
payment page
Purchasing SparkNotes PLUS for a group?
Get Annual Plans at a discount when you buy 2 or more!
Price
$24.99 $18.74 /subscription + tax
Subtotal $37.48 + tax
Save 25% on 2-49 accounts
Save 30% on 50-99 accounts
Want 100 or more? Contact us for a customized plan.
payment page
Your Plan
Payment Details
Payment Summary
SparkNotes Plus
You'll be billed after your free trial ends.
7-Day Free Trial
Not Applicable
Renews May 19, 2024 May 12, 2024
Discounts (applied to next billing)
DUE NOW
US $0.00
SNPLUSROCKS20 | 20% Discount
This is not a valid promo code.
Discount Code (one code per order)
SparkNotes PLUS Annual Plan - Group Discount
Qty: 00
SparkNotes Plus subscription is $4.99/month or $24.99/year as selected above. The free trial period is the first 7 days of your subscription. TO CANCEL YOUR SUBSCRIPTION AND AVOID BEING CHARGED, YOU MUST CANCEL BEFORE THE END OF THE FREE TRIAL PERIOD. You may cancel your subscription on your Subscription and Billing page or contact Customer Support at custserv@bn.com. Your subscription will continue automatically once the free trial period is over. Free trial is available to new customers only.
Choose Your Plan
For the next 7 days, you'll have access to awesome PLUS stuff like AP English test prep, No Fear Shakespeare translations and audio, a note-taking tool, personalized dashboard, & much more!
You’ve successfully purchased a group discount. Your group members can use the joining link below to redeem their group membership. You'll also receive an email with the link.
Members will be prompted to log in or create an account to redeem their group membership.
Thanks for creating a SparkNotes account! Continue to start your free trial.
We're sorry, we could not create your account. SparkNotes PLUS is not available in your country. See what countries we’re in.
There was an error creating your account. Please check your payment details and try again.
Please wait while we process your payment
Your PLUS subscription has expired
Please wait while we process your payment
Please wait while we process your payment
When learning linear search, you were asked to perform an exercise with a phone book. Go get the phonebook again. Let's say we're looking for the name 'John Smith'. Open up the phone book approximately half way and look at the name at the top of the page. What does it say? Probably a name that begins with an 'M' or some letter in that vicinity. Now think to yourself, does Smith come before or after this in the phonebook? After, right? So you can ignore the entire first half of the phone book. Now open the remaining half about half way. You're probably somewhere near the 'T's. Does Smith come before or after 'T' in the phonebook? Before. So you can ignore the latter half. Continue doing this until you find the name for which you're looking.
What you've just done is a binary search. Binary search involves binary decisions, decisions with two choices. At each step in the process you can eliminate half of the data you're searching. This is the way humans look up most information in big volumes, such as a phonebook or a dictionary. We guess a place in the middle of the book, then move forward or backward depending on the location you're at relative to the location of what you're looking for. This works because all of the data is sorted, in alphabetical order in the case of a phonebook or dictionary.
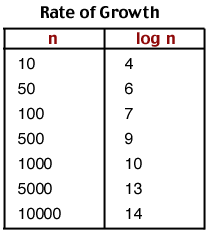
Binary search is much faster than linear search for most data sets. If you look at each item in order, you may have to look at every item in the data set before you find the one you are looking for. With binary search, you eliminate half of the data with each decision. If there are n items, then after the first decision you eliminate n/2 of them. After the second decision you've eliminated 3n/4 of them. After the third decision you've eliminated 7n/8 of them. Etc. In other words, binary search is O(logn). You can see that for a large data set, binary search would be much better than linear search.
Please wait while we process your payment



