
 payment page
payment pageA problem we haven't looked at much, and will only touch on briefly in this guide, is string searching, the problem of finding a string within another string. For example, when you execute the "Find" command in your word processor, your program starts at the beginning of the string holding all the text (let's assume for the moment that this is how your word processor stores your text, which it probably doesn't) and searches within that text for another string you've specified.
The most basic string searching method is called the "brute-force" method. The brute force method is simply a search through all the possible solutions to the problem. Each possible solution is tested until one that works is found.
Brute-force String Searching
We'll call the string being searched "text string" and the string being searched for "pattern string". The algorithm for Brute-force search works as follows: 1. Start at the beginning of the text string. 2. Compare the first n characters of the text string (where n is the length of the pattern string) to the pattern string. Do they match? If yes, we're done. If no, continue. 3. Shift over one place in the text string. Do the first n characters match? If yes, we're done. If no, repeat this step until we either reach the end of the text string without finding a match, or until we find a match.
The code for it would look something like this:
This works, but as we've seen previously just working isn't enough. What is the efficiency of brute-force search? Well, each time we compare the strings, we do M comparisons, where M is the length of the pattern string. And how many times do we do this? N times, where N is the length of the text string. So brute-force string search is O(MN). Not so good.
How can we do better?
Rabin-Karp String Search
Michael O. Rabin, a professor at Harvard University, and Richard Karp devised a method for using hashing to do string search in O(M + N), as opposed to O(MN). In other words, in linear time as opposed to quadratic time, a nice speedup.
The Rabin-Karp algorithm uses a technique called fingerprinting.
1. Given the pattern of length n, hash it. 2. Now hash the first n characters of the text string. 3. Compare the hash values. Are they the same? If not, then it is impossible for the two strings to be the same. If they are, then we need to do a normal string comparison to check if they are actually the same string or if they just hashed to the same value (remember that two different strings can hash to the same value). If they match, we're done. If not, we continue. 4. Now shift over a character in the text string. Get the hash value. Continue as above until the string is either found or we reach the end of the text string.
Now you may be wondering to yourself, "I don't get it. How can this be anything less than O(MN) as to create the hash for each place in the text string, don't we have to look at every character in it?" The answer is no, and this is the trick that Rabin and Karp discovered.
The initial hashes are called fingerprints. Rabin and Karp discovered a way to update these fingerprints in constant time. In other words, to go from the hash of a substring in the text string to the next hash value only requires constant time. Let's take a simple hash function and look at an example to see why and how this works.
We'll use a simply hash function to make our lives easier. All this hash function does is add up the ASCII values of each letter, and mod it by some prime number:
Now let's take an example. Let's say our pattern is "cab". And let's say our text string is "aabbcaba". For the sake of clarity, we'll use 0 through 26 here to represent letters as opposed to their actual ASCII values.
First, we hash "abc", and find that hash("abc") == 0. Now we hash the first three characters of the text string, and find that hash("aab") == 1.
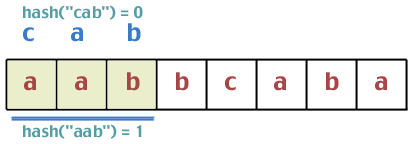
Do they match? Does 1 = = 0? No. So we can move on. Now comes the problem of updating the hash value in constant time. The nice thing about the hash function we used is that it has some properties which allow us to do this. Try this. We started with "aab" which hashed to 1. What is the next character? 'b'. Add 'b' to this sum, resulting in 1 + 1 = 2. What was the first character in the previous hash? 'a'. So subtract 'a' from 2; 2 - 0 = 2. Now take the modulo again; 2%3 = 2. So our guess is that when sliding the window over, we can just add the next character that appears in the text string, and delete the first character that is now leaving our window. Does this work? What would the hash value be of "abb" if we did it the normal way: (0 + 1 + 1)%2 = 2. Of course, this doesn't prove anything, but we won't do a formal proof. If it bothers you that much, do it as an exercise.
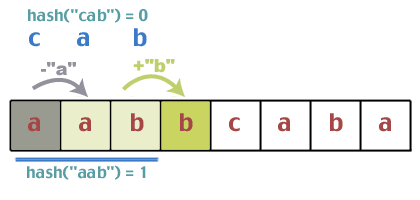
The code used to do the update would look something like:
Let's continue with the example. The update is now complete and the text we're matching against is "abb":
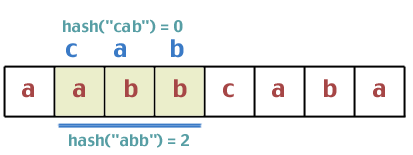
The hash values are different, so we continue. Next:
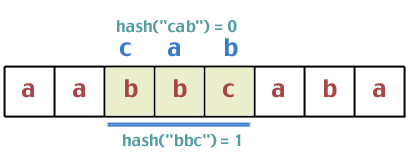
Different hash values. Next:
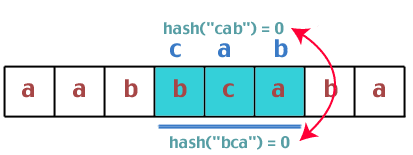
Hmm. These two hash values are the same, so we need to do a string comparison between "bca" and "cab". Are they the same? No. So we continue:
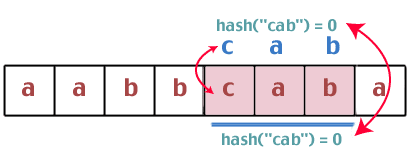
Again, we find that the hash values are the same, so we compare the strings "cab" and "cab". We have a winner.
The code for doing Rabin-Karp as above would look something like:



