Did you know you can highlight text to take a note?
x

Please wait while we process your payment
If you don't see it, please check your spam folder. Sometimes it can end up there.
If you don't see it, please check your spam folder. Sometimes it can end up there.
Please wait while we process your payment
Get instant, ad-free access to our grade-boosting study tools with a 7-day free trial!
Learn more

![]()
Create Account
Select Plan
Payment Info
Start 7-Day Free Trial!
Create Account
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Log into your PLUS account
Create Account
Select Plan
Payment Info
Start 7-Day Free Trial!
Select Your Plan
Monthly
$5.99
/month + tax
Annual
$29.99
/year + taxAnnual
2-49 accounts
$22.49/year + tax
50-99 accounts
$20.99/year + tax
Select Quantity
Price per seat
$29.99 $--.--
Subtotal
$-.--
Want 100 or more? Request a customized plan
Monthly
$5.99
/month + taxYou could save over 50%
by choosing an Annual Plan!

Annual
$29.99
/year + taxSAVE OVER 50%
compared to the monthly price!
| Focused-studying | ||
| PLUS Study Tools | ||
| AP® Test Prep PLUS | ||
| My PLUS Activity | ||
Annual
$22.49/month + tax
Save 25%
on 2-49 accounts
Annual
$20.99/month + tax
Save 30%
on 50-99 accounts
| Focused-studying | ||
| PLUS Study Tools | ||
| AP® Test Prep PLUS | ||
| My PLUS Activity | ||
Testimonials from SparkNotes Customers
No Fear provides access to Shakespeare for students who normally couldn’t (or wouldn’t) read his plays. It’s also a very useful tool when trying to explain Shakespeare’s wordplay!
Erika M.
I tutor high school students in a variety of subjects. Having access to the literature translations helps me to stay informed about the various assignments. Your summaries and translations are invaluable.
Kathy B.
Teaching Shakespeare to today's generation can be challenging. No Fear helps a ton with understanding the crux of the text.
Kay H.
Testimonials from SparkNotes Customers
No Fear provides access to Shakespeare for students who normally couldn’t (or wouldn’t) read his plays. It’s also a very useful tool when trying to explain Shakespeare’s wordplay!
Erika M.
I tutor high school students in a variety of subjects. Having access to the literature translations helps me to stay informed about the various assignments. Your summaries and translations are invaluable.
Kathy B.
Teaching Shakespeare to today's generation can be challenging. No Fear helps a ton with understanding the crux of the text.
Kay H.
Create Account
Select Plan
Payment Info
Start 7-Day Free Trial!
Payment Information
You will only be charged after the completion of the 7-day free trial.
If you cancel your account before the free trial is over, you will not be charged.
You will only be charged after the completion of the 7-day free trial. If you cancel your account before the free trial is over, you will not be charged.
Order Summary
Annual
7-day Free Trial
SparkNotes PLUS
$29.99 / year
Annual
Quantity
51
PLUS Group Discount
$29.99 $29.99 / seat
Tax
$0.00
SPARK25
-$1.25
25% Off
Total billed on Nov 7, 2024 after 7-day free trail
$29.99
Total billed
$0.00
Due Today
$0.00
Promo code
This is not a valid promo code
Card Details
By placing your order, you confirm that you have read the Privacy Policy and Kids’ Privacy Notice and agree to the Terms of Service.
By saving your payment information you allow SparkNotes to charge you for future payments in accordance with their terms.
Powered by stripe
Legal
Google pay.......

Thank You!
Your group members can use the joining link below to redeem their membership. They will be prompted to log into an existing account or to create a new account. All members under 16 will be required to obtain a parent's consent sent via link in an email.Your Child’s Free Trial Starts Now!
Thank you for completing the sign-up process. Your child’s SparkNotes PLUS login credentials are [email] and the associated password. If you have any questions, please visit our help center.Your Free Trial Starts Now!
Please wait while we process your payment
Sorry, you must enter a valid email address
By entering an email, I confirm that I or my legal guardian has read the Privacy Policy and Kids’ Privacy Notice and agrees to the Terms of Service.
Please wait while we process your payment
Sorry, you must enter a valid email address
By entering an email, I confirm that I or my legal guardian has read the Privacy Policy and Kids’ Privacy Notice and agrees to the Terms of Service.
Please wait while we process your payment
Your PLUS subscription has expired
Please wait while we process your payment
Please wait while we process your payment
Month
Day
Year
Please read our terms and privacy policy
Please wait while we process your payment
Square Roots
The square root of a number is the number that, when squared (multiplied
by itself), is equal to the given number. For example, the square root of 16,
denoted 161/2 or 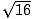 , is 4, because 42 = 4×4 = 16. The square
root of 121, denoted
, is 4, because 42 = 4×4 = 16. The square
root of 121, denoted 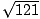 , is 11, because 112 = 121.
, is 11, because 112 = 121.
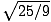 = 5/3, because (5/3)2 = 25/9.
= 5/3, because (5/3)2 = 25/9.
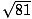 = 9, because 92 = 81. To take the square root of a
fraction, take the square root of the numerator and the square root of the
denominator. The square root of a number is always positive.
= 9, because 92 = 81. To take the square root of a
fraction, take the square root of the numerator and the square root of the
denominator. The square root of a number is always positive.
All perfect squares have square roots that are whole numbers. All fractions
that have a perfect square in both numerator and denominator have square roots
that are rational numbers.
For example, 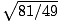 = 9/7. All other positive numbers have
squares that are non-terminating, non-
repeating decimals, or irrational
numbers. For example,
= 9/7. All other positive numbers have
squares that are non-terminating, non-
repeating decimals, or irrational
numbers. For example, 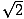 = 1.41421356... and
= 1.41421356... and 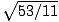 = 2.19503572....
= 2.19503572....
Since a positive number multiplied by itself (a positive number) is always positive, and a negative number multiplied by itself (a negative number) is always positive, a number squared is always positive. Therefore, we cannot take the square root of a negative number.
Taking a square root is almost the inverse
operation of taking a square. Squaring a positive
number and then taking the square root of the result does not change the number:
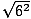 =
= 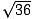 = 6. However, squaring a
negative number and then taking the square root of the result is equivalent to
taking the opposite of the negative
number:
= 6. However, squaring a
negative number and then taking the square root of the result is equivalent to
taking the opposite of the negative
number: 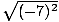 =
= 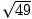 = 7. Thus, we
conclude that squaring any number and then taking the square root of the
result is equivalent to taking the absolute value of the given number. For example, = | 6| = 6, and
= | - 7| = 7.
= 7. Thus, we
conclude that squaring any number and then taking the square root of the
result is equivalent to taking the absolute value of the given number. For example, = | 6| = 6, and
= | - 7| = 7.
Taking the square root first and then squaring the result yields a slightly
different case. When we take the square root of a positive number and then
square the result, the number does not change: ()2 = 112 = 121. However, we cannot take the square root of a negative
number and then square the result, for the simple reason that it is impossible
to take the square root of a negative number.
A cube root is a number that, when cubed, is equal to the given number. It is denoted with an exponent of "1/3". For example, the cube root of 27 is 271/3 = 3. The cube root of 125/343 is (125/343)1/3 = (1251/3)/(3431/3) = 25/7.
Please wait while we process your payment



