
 payment page
payment pageNote: This guide is not intended as a fully comprehensive guide to sorting, only a glimpse at how recursion can be used to effectively sort. For more information on the sorting algorithms described within (as well as other algorithms not mentioned), please see the SparkNote guide to sorting algorithms.
Recursive techniques can be utilized in sorting algorithms, allowing for the sorting of n elements in O(nlogn) time (compared with the O(n2) efficiency of bubble sort. Two such algorithms which will be examined here are Mergesort and Quicksort.
Mergesort
To discuss mergesort, we must first discuss the merge operation, the process of combining to sorted data sets into one sorted data set. The merge operation can be accomplished in O(n) time.
Given two sorted data sets to merge, we start at the beginning of each:
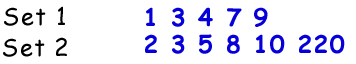
We take the smallest element from the two we're comparing (these being the two elements at the front of the sets), and we move it into the new data set. This repetition is done until all of the elements have been moved, or until one of the lists is empty, at which point all of the elements in the non-empty list are moved to the new list, leaving them in the same order.
The following code implements the merge operation. It merges a1[] and a2[], and stores the merged list back into a1[] (therefore a1[] must be large enough to hold both lists):
This merge operation is key to the mergesort algorithm.
Mergesort is a divide-and-conquer algorithm, meaning that it accomplishes its task by dividing up the data in order to better handle it. Mergesort has the following algorithm: split the list in half, sort each side, then merge the two sides together. See the recursive aspect? The second step of the mergesort algorithm is to sort each half. What algorithm might we use to sort each half of the set? In the spirit of recursion, we'll use mergesort.
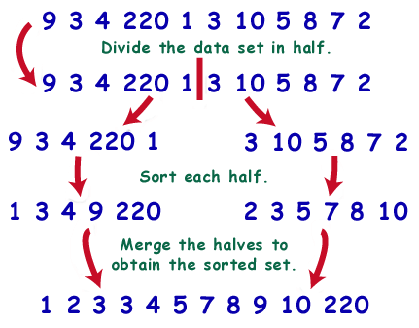
Just as with binary search, mergesort continually splits the data set in half, doing O(n) operations at each level of recursion. There are O(logn) splits of the data set. Therefore, mergesort() runs in O(nlogn) time, the provably best efficiency for a comparison-based sort.
Quicksort
Quicksort, an algorithm developed by C.A.R. Hoare in the 1960s, is one of the most efficient sorting algorithms; for a large, random data set, it is often considered to be the fastest sort. Like mergesort(), it is also a divide-and-conquer algorithm resulting in an average case running time of O(nlogn).
Like mergesort, quicksort partitions the data into two sets. The algorithm for quicksort is as follows: choose a pivot value (a value to which we'll compare the rest of the data in the set), put all values smaller than that pivot on one side of the set and all values greater than that pivot on the other side of the set, then sort each half. Again, we'll recursively sort each half of the data set using the same algorithm, quicksort.

Sometimes when the size of the partition gets small enough, a programmer will use another non-recursive sorting algorithm, like selection sort or bubble sort (see the SparkNote guide on sorting if you are unfamiliar with this sort), to sort the small sets; this often counters the inefficiency of many recursive calls.
There are many variants of the basic quicksort algorithm, such as different methods for picking a pivot value (most of which are better than the one used above), methods for partitioning the data, different thresholds for stopping the recursion, etc. For more information, please refer to the SparkNote guide to sorting.



